Clinical Report: Enhancing Voice Disorder Classification Through Data-Driven Improvements
Background
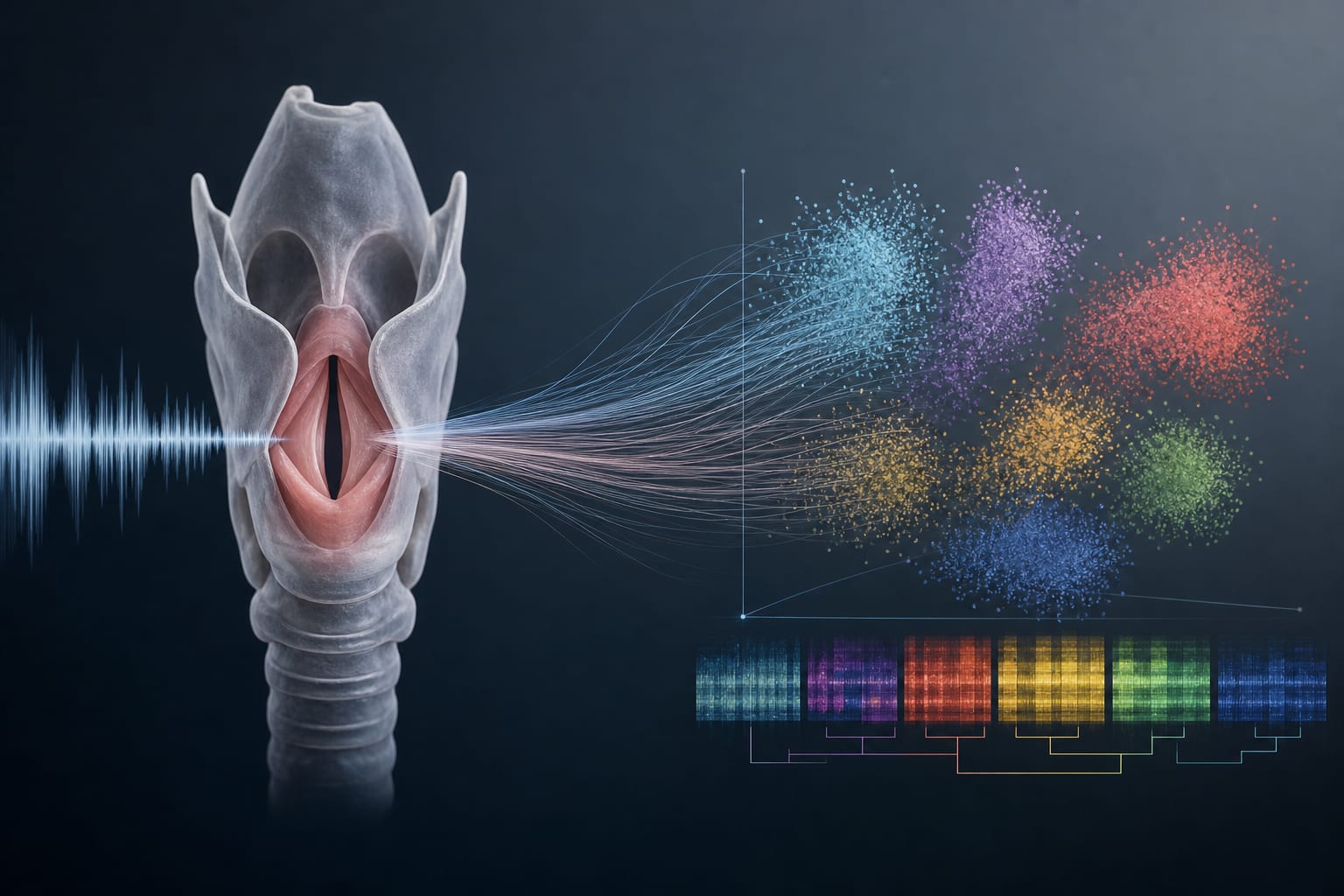
Voice disorders are critical indicators of impaired vocal function and serve as a valuable testbed for developing AI-driven acoustic analysis methods. Accurate classification of these disorders is essential for leveraging voice as a biomarker in healthcare. Current multi-class classification systems face significant challenges, achieving only 50%-60% balanced accuracy, which limits their clinical applicability. [Citation needed]
Data Highlights
Framework
Balanced Accuracy
CarLab 2025
67.20%
Best-performing Clinical Framework
61.03%
Key Findings
CarLab 2025 achieved superior in-domain classification accuracy compared to established clinical taxonomies.
Models trained with structured taxonomies outperformed those with narrow, single-disorder labels for out-of-domain generalisation.
Training on diverse vocal tasks improved cross-database performance more effectively than single-task training.
Injecting a small amount of data from target domains boosted binary detection accuracy but did not consistently enhance multi-class recall.
Robust multi-class generalisation requires diverse multi-source training data.
Clinical Implications
The findings suggest that aligning classification frameworks with acoustic manifestations of voice disorders may enhance diagnostic accuracy.
Conclusion
The development of CarLab 2025 provides an approach to improving voice disorder classification, addressing existing performance gaps in multi-class detection tasks.