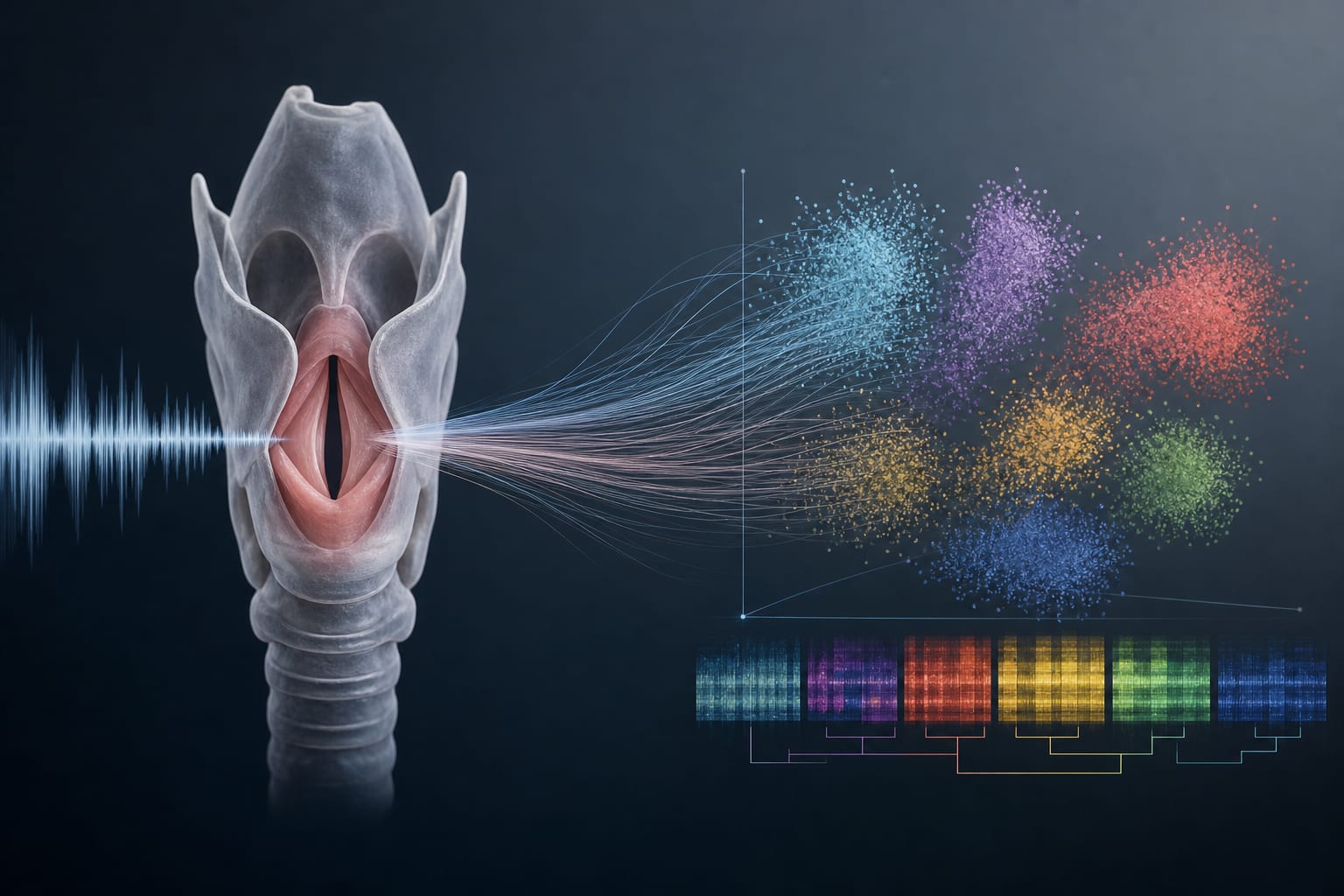
To establish a more model-aligned and generalizable foundation for voice disorder classification by deriving a taxonomy from data-driven acoustic relationships.
Approach:
Key Findings:
CarLab 2025 achieved a balanced accuracy of 67.20%, outperforming the best clinical framework at 61.03%.
Models trained with structured taxonomies outperformed those with narrow, single-disorder labels for out-of-domain generalization.
Training on diverse vocal tasks was more effective for cross-database performance than relying on a single task.
Multi-task learning did not provide advantages over single-task training.
Injecting a small amount of data from target domains improved binary detection accuracy but did not consistently enhance multi-class recall.
Interpretation:
The results indicate that aligning classification frameworks with acoustic manifestations of disorders can improve performance in voice disorder classification.
Limitations:
Robust multi-class generalization requires substantially more diverse multi-source training data.
The study's findings may not be generalizable to all voice disorder types or populations.
Conclusion:
The study provides a pathway toward developing more robust and generalizable models for vocal pathology detection.