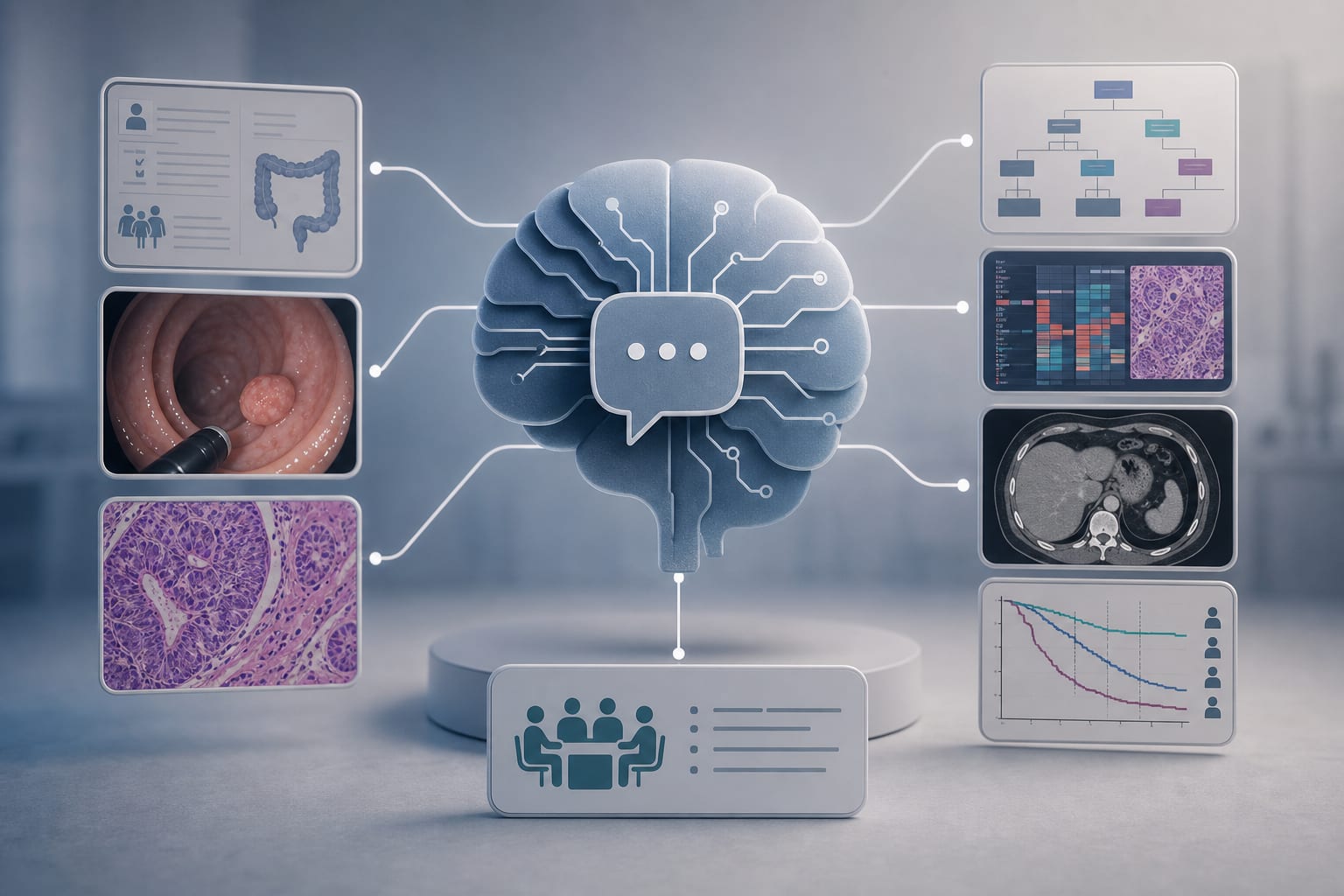
To evaluate the performance of different LLM categories across the full CRC care continuum and identify evidence gaps arising from fragmented research practices.
Key Findings:
LLMs can automate extraction and processing of clinical follow-up records and provide real-time responses to patient inquiries.
Research on LLMs in CRC has rapidly expanded, with applications in screening, diagnosis, and therapeutic decision support.
Heterogeneity in model selection, prompt engineering strategies, and evaluation metrics limits generalizability of findings.
Interpretation:
Limitations:
Inaccurate outputs due to hallucinations.
Quality assurance concerns in complex diagnostic and therapeutic recommendations.
Challenges related to model bias and limited generalizability.